多模态大模型可以理解成:一个以大语言模型为“大脑”,把图像、语音、视频等模态先编码成“类似文字 token 的表示”,再交给 LLM 推理和生成的系统。
典型结构如下:
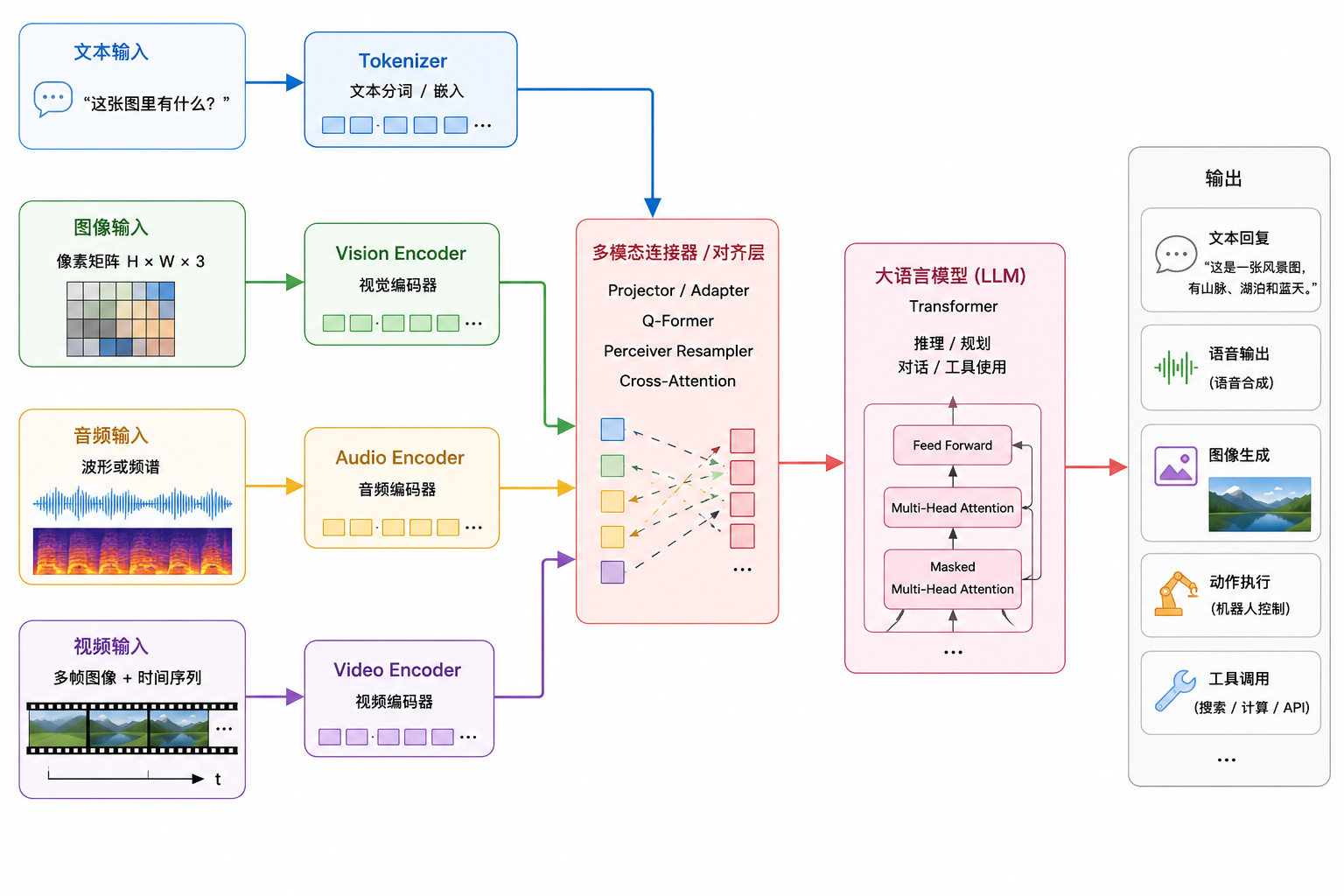
1. 输入层:不同模态各走各的入口#
不同数据不能直接送进语言模型。
比如:
文字:“这张图里有什么?”
图像:像素矩阵 H × W × 3
音频:波形或频谱
视频:多帧图像 + 时间序列所以第一步是把它们变成向量表示。
- 文字会经过 tokenizer,变成文本 token
- 图像通常经过 ViT、CLIP Vision Encoder、ConvNeXt 等视觉编码器
- 音频可能经过 Whisper encoder、HuBERT、wav2vec 等音频编码器
- 视频则通常是“抽帧 + 视觉编码器 + 时间建模”。
2. 模态编码器:把非文字变成特征#
以图像为例,视觉编码器会把图片切成 patch:
图片
→ patch1, patch2, patch3, ...
→ 视觉向量 z1, z2, z3, ...这些向量还不是语言模型能直接理解的 token,需要加入连接器来转换成 LLM 可以理解的 token,因为它们所在的“向量空间”和 LLM 的词向量空间不同。
LLaVA 就是一个典型例子:它把预训练的 CLIP ViT-L/14 视觉编码器和 Vicuna 语言模型连接起来,中间用一个投影层做视觉到语言空间的映射。(LLaVA ↗)
3. 连接器:多模态模型的关键桥梁#
连接器的作用是:
视觉特征空间 → 语言模型 embedding 空间常见连接器有几类:
| 连接器类型 | 作用 | 代表思路 |
|---|---|---|
| Linear Projector | 一个线性层,简单把视觉向量映射到 LLM 维度 | LLaVA 早期结构 |
| MLP Projector | 多层感知机,表达能力更强 | LLaVA-1.5 等 |
| Q-Former | 用一组可学习 query 从视觉特征中提取信息 | BLIP-2 |
| Perceiver Resampler | 把大量视觉 token 压缩成固定数量 token | Flamingo |
| Cross-Attention | LLM 在生成时动态关注视觉特征 | Flamingo 等 |
很多现代 MLLM 的基本思路都是:视觉编码器产生视觉 patch embeddings,连接器把它们投影成语言模型可接收的 embedding,然后这些视觉 embedding 作为“软提示词”与文本 token 一起送入 LLM。(Springer ↗)
4. 大语言模型:负责推理、对话和生成#
LLM 是核心“大脑”。
输入给 LLM 的序列大概长这样:
[视觉token1] [视觉token2] ... [视觉tokenN]
[用户文本token1] [用户文本token2] ...然后 LLM 像处理普通文本一样做自回归生成:
用户:这张图里的人在做什么?
模型:图中有一个人正在……本质上,LLM 并不是直接“看像素”,而是看到了由视觉编码器和连接器转化后的视觉 token。
5. 两种主流架构范式#
A. “编码器 + 投影层 + LLM”结构#
这是最常见、最容易理解的一类。
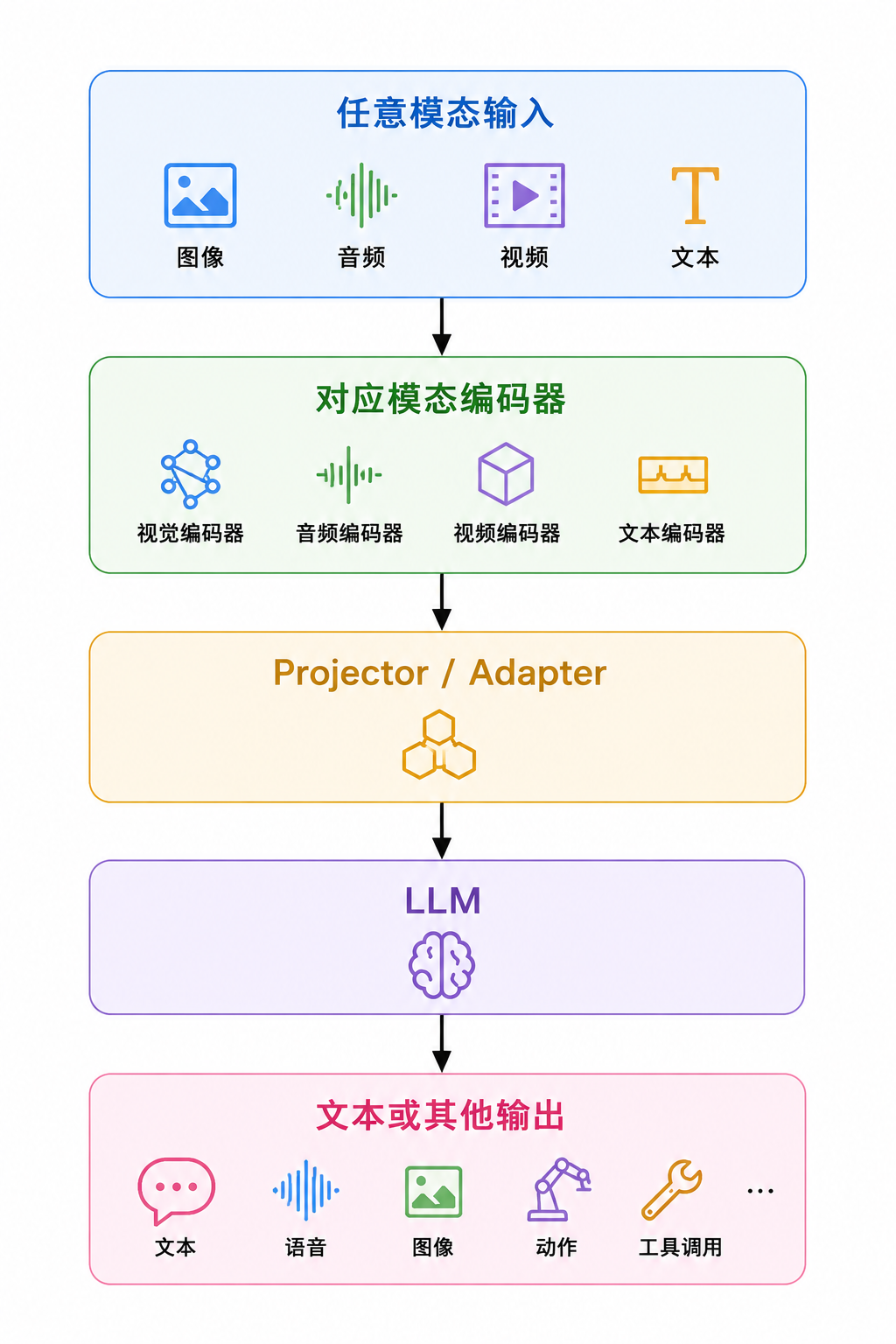
图片 → 视觉 token → 拼进输入 → LLM代表:LLaVA、MiniGPT-4、InstructBLIP 的部分思想。
优点是结构简单,容易训练和扩展。LLaVA 官网描述的核心结构就是“CLIP 视觉编码器 + 投影矩阵 + Vicuna 语言模型”。(LLaVA ↗)
B. “视觉特征 + Cross-Attention 注入 LLM”结构#
这类不是简单地把视觉 token 拼到文本前面,而是在 LLM 的若干层中加入 cross-attention,让语言模型生成时去“查阅”视觉信息。
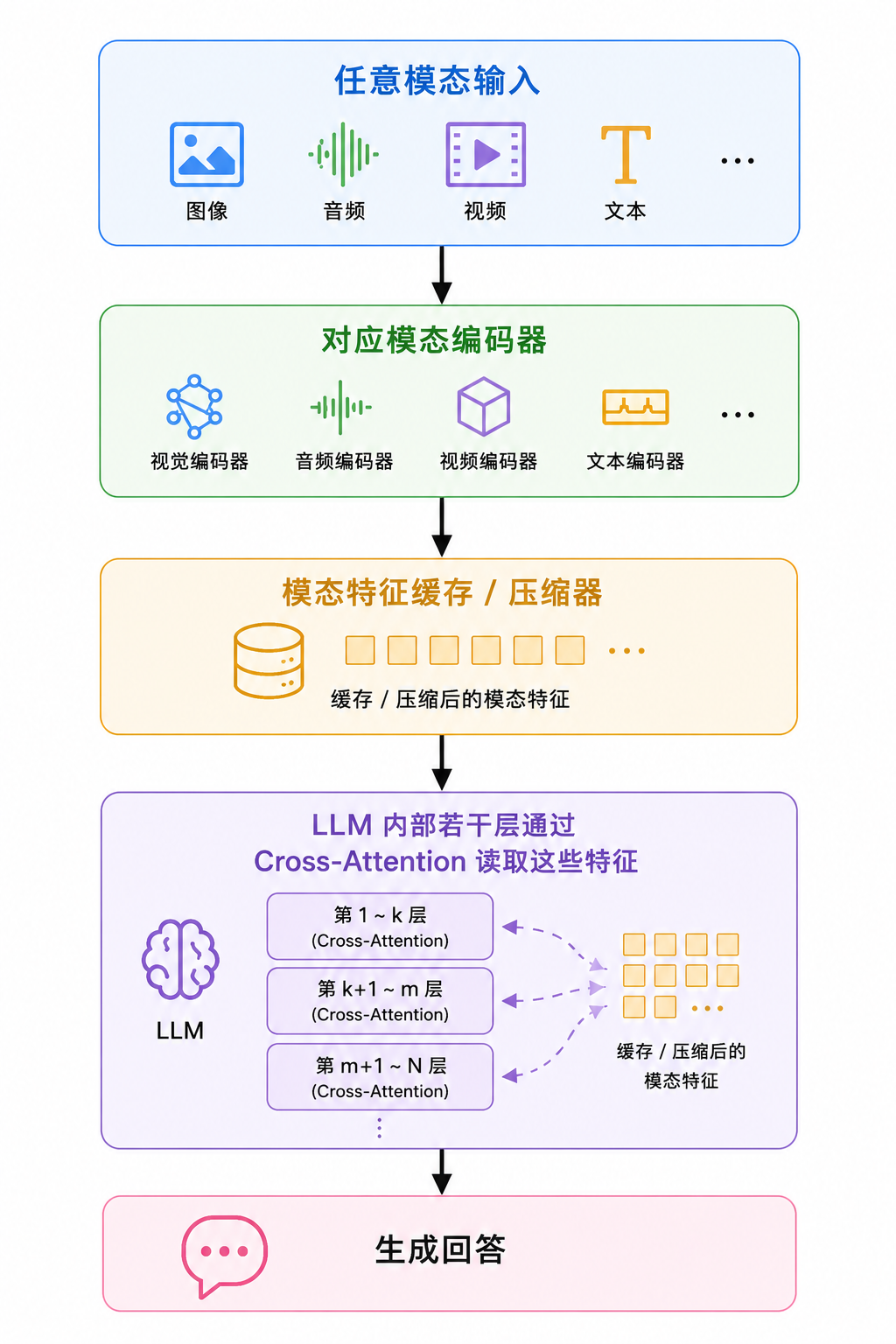
图片 → 视觉特征 → 放在旁边
LLM 内部通过 cross-attention 反复读取代表:Flamingo。
Flamingo 的关键设计包括 Perceiver Resampler 和 gated cross-attention,用来把视觉信息接入语言模型,并支持图像、视频与文本交错输入。(arXiv ↗)
6. 更完整的现代多模态大模型结构#
如果是更强的模型,结构可能会变成这样:
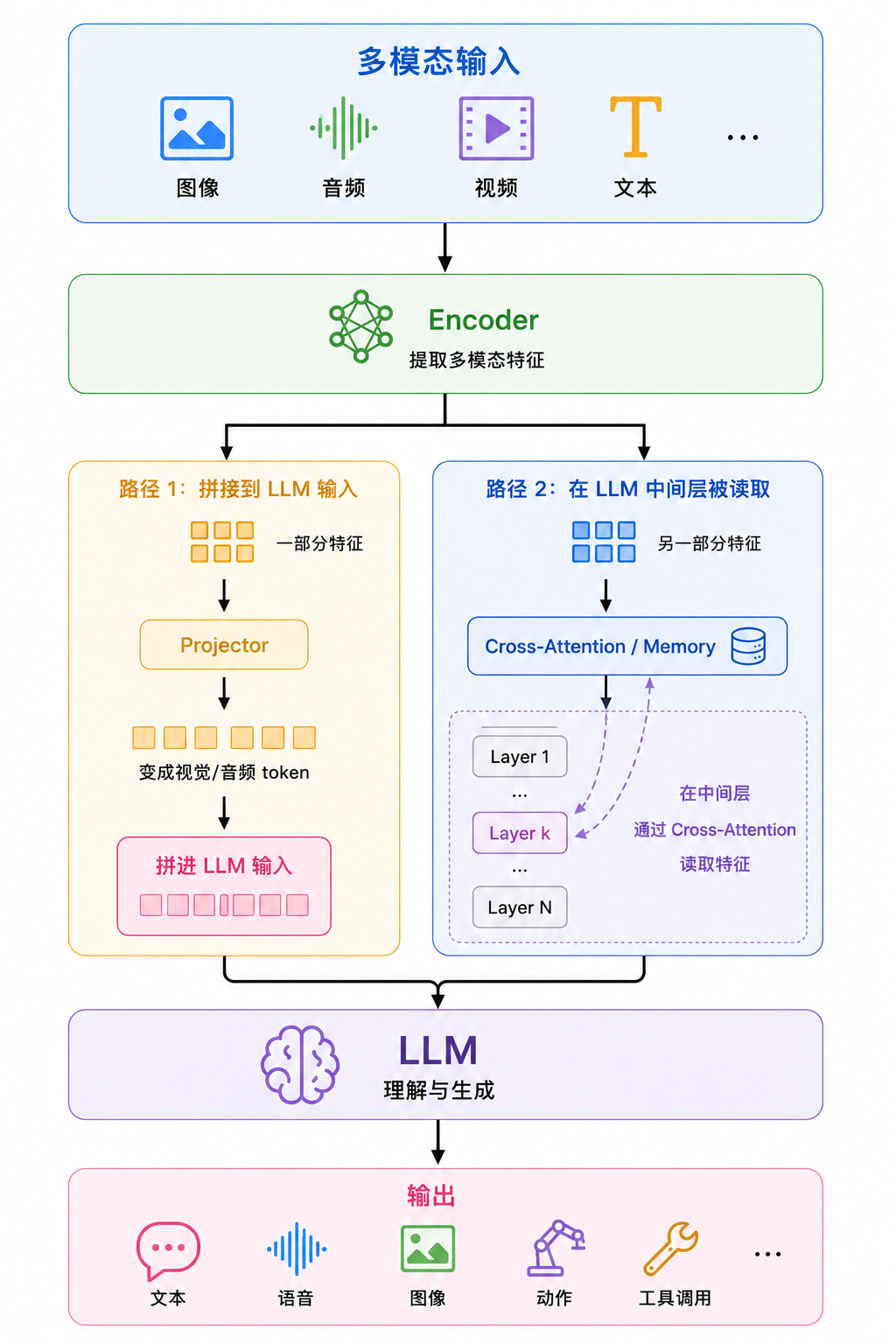
一些 survey 会把典型 MLLM 概括为三个核心组件:modality encoder、connector、LLM,有些系统还会在后面接 generator,用于生成图像、音频等非文本模态。(OpenReview ↗)
7. 训练通常分几步#
多模态大模型一般不是从零训练全部模块,而是组合已有强模型,然后对齐。
常见训练流程:
第一阶段:模态对齐
图像-文本对,比如 caption 数据
目标:让视觉 token 能被 LLM 理解
第二阶段:指令微调
多模态问答、图文对话、OCR、推理数据
目标:让模型学会按人类指令回答
第三阶段:偏好优化
RLHF / DPO / RLAIF
目标:让回答更安全、更有用、更符合人类偏好LLaVA 采用的就是两阶段思路:先做视觉-语言特征对齐,再做视觉指令微调。(LLaVA ↗)
8. 一个具体例子:看图问答时内部发生什么#
用户上传图片并问:
这张图里的狗在做什么?模型内部大概是:
1. 图片 → Vision Encoder
得到一串视觉特征
2. 视觉特征 → Projector
变成 LLM 能读的视觉 token
3. 文本问题 → Tokenizer
变成文本 token
4. 拼接:
[视觉token][问题token]
5. LLM 推理:
识别主体:狗
识别动作:跑、睡觉、接飞盘等
组织语言回答
6. 输出:
“这只狗正在草地上奔跑。”9. 总结#
多模态大模型的结构本质是:
多模态编码器负责“看见/听见”
连接器负责“翻译成 LLM 能懂的表示”
LLM 负责“理解、推理、回答”
输出模块负责“生成文本或其他模态”所以,多模态大模型并不是一个单纯的“大 Transformer 什么都吃”,而通常是一个模块化系统:前面有不同模态的编码器,中间有跨模态对齐模块,后面有大语言模型作为统一推理核心。